Fast R-CNN
Links
- PDF Attachments: 2015’Fast R-CNN_Girshick_.pdf
- Zotero Links: Local library
My Comments and Inspiration
Contributions and Important Conclusions
Contributions
- 比 R-CNN 和 SSPNet 的结果更好 (mAP),速度更快
- End-to-end training.
- 不需要占用额外的磁盘空间做特征缓存1
Motivation
Introduction
精准的目标检测引发了两个主要的挑战
- 需要处理数量众多的候选框,消耗了大量的时间(RCNN中每个RoI都需要分别提取特征)
- 这些候选框大多都只是粗定位(rough localization),因此需要进一步精细化(precise localization)。
R-CNN 的缺点
- 多阶段的模型,导致训练不是端到端的。类别预测、bbox 回归都是不同的模型,要分别训练,保存中间结果后送到后面的模型中
- 训练花费的空间和时间都十分巨大,即训练速度慢,占用大量磁盘空间(做特征缓存)。训练速度慢的主要原因是需要对每一个proposal的内容送入CNN做特征提取,没有共享计算结果。
- 目标检测的推理速度慢(在一个 GPU 上使用 VGG16,约 47s 处理一张图片)。
SPPNet 的改进和缺点
- 通过共享计算加速了 R-CNN
- 不能不做端到端的训练,SS 层之前的网络无法反向传播到。
- 等等,没读 SSPNet,因此看不懂。
Fast R-CNN
- 全称为 Fast Region-based Convolutional Network method
- 核心模块为 ROI Pooling Layer 和 Multi Task Loss
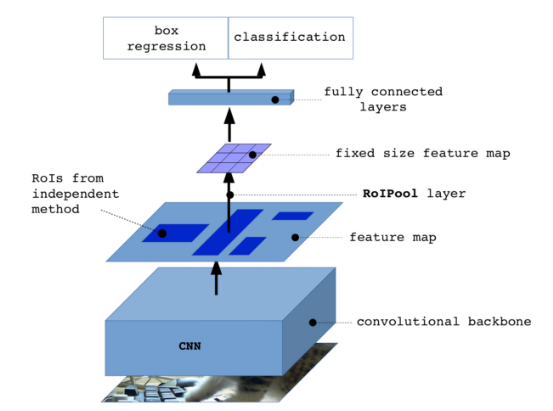
其过程如下
- 使用 Selective Search 生成约2000个候选框(Region Proposal)
- 将原始图片送到 backbone 中进行特征提取,得到特征图
- 将候选框的位置投影到特征图上,进而裁切出候选框对应的特征图
- 利用 ROI Pooling 来将不同尺寸的候选特征图 pooling 到相同大小
- 送入到后续的网络中完成分类和回归
特别说明:
- 第四步后,作者直接将得到的等大小的特征图Resize成一维向量了,后面的网络也都是由FC组成的
- 分类和回归是两个并联的 FC
- 对于每个候选框,分类网络输出其 K+1 个类别的概率(K 个物体类别,1 个背景类别)
- 对于每个候选框,回归网络输出4个参数
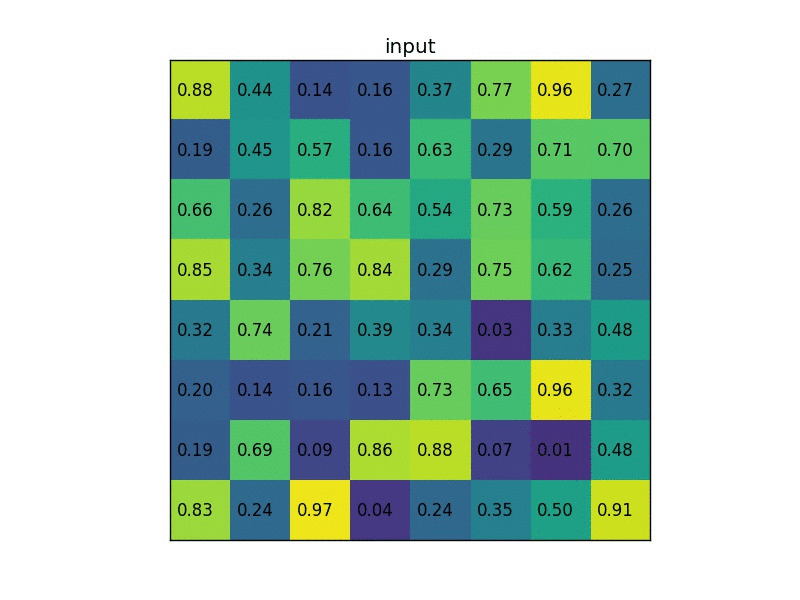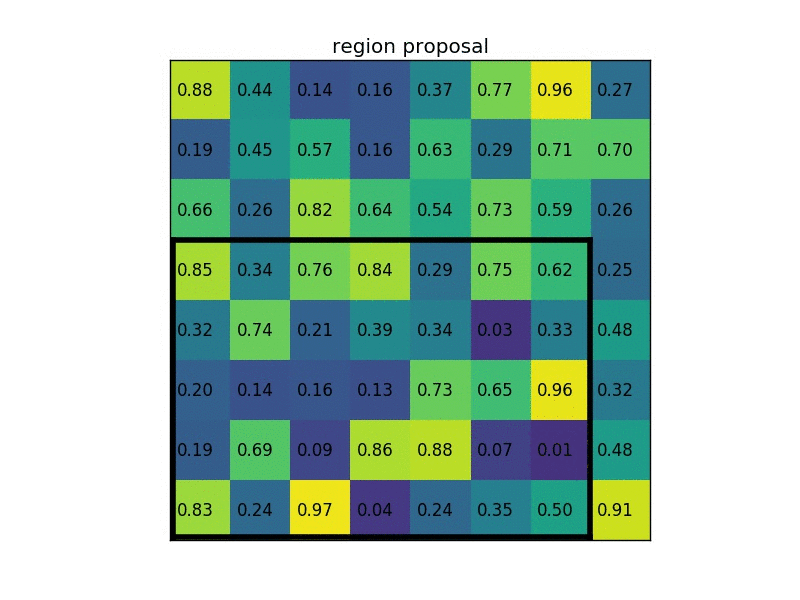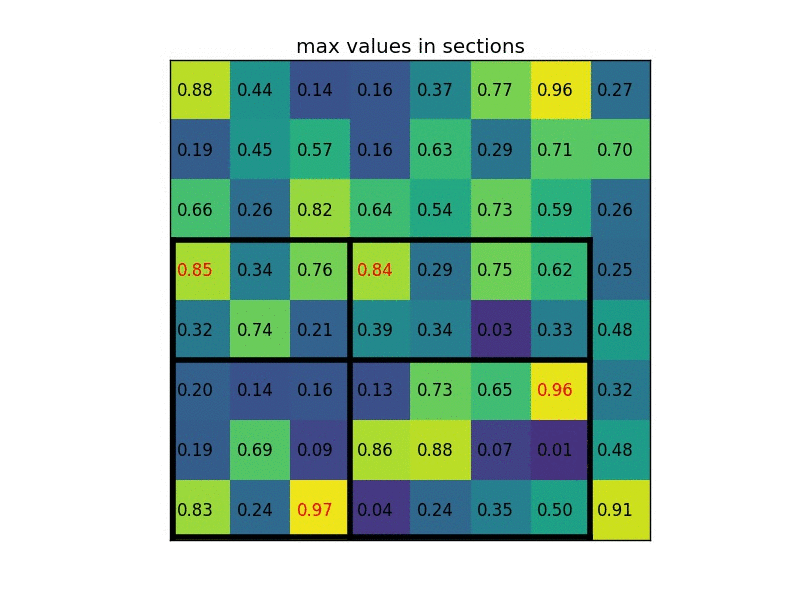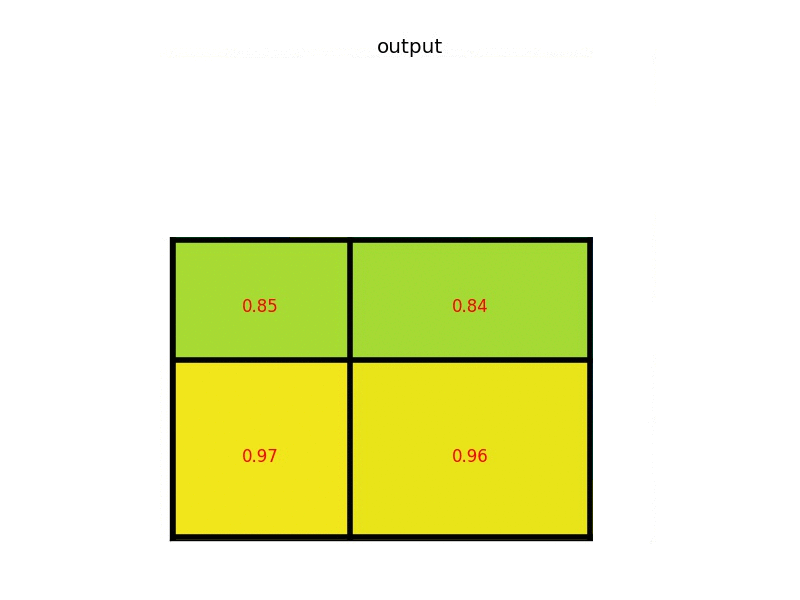
ROI Pooling Layer
作用: 将任意尺寸的 Feature map 转换成固定尺寸的小 Feature map
过程: 假设一个 ROI pooling layer 输出固定尺寸为 H*W 的特征图,并给定输入为任意尺寸的 Feature map (c*h*w)
- 将输入的特征图平均切分成 H*W 个patch,每个patch的尺寸为
- 每个patch上做 max pooling, 注意通道上是独立的(和标准的 max pooling 一样,输入输出的通道数一样,不过这里 pooling 尺寸是由格子的大小决定的)
- 这样每个格子会得到 c*1 的特征向量,考虑在 H*W 个 patch 上做 max pooling,即整个输出的特征图的尺寸为 c*H*W
下图我们以输入任意尺寸的proposal,并固定输出2x2的特征图为例
损失函数
Fast R-CNN 最终的输出是两个并联的 FC,分别完成预测任务和 bbox 回归的任务,每个任务对应一个loss function.
- 分类任务 对于完成预测类别任务的 FC,其输出的是每个候选框属于每个类 (假设共有 K 类) 的概率 。这里共有 K+1 类,其中第 0 类表示”背景”类别。 该分支使用 Softmax 作为损失函数,表示当前候选框的正确类别,表示预测结果
这里实际上是一个多分类的交叉熵损失函数简化后的样子
- bbox回归任务 对于完成 bbox 回归任务的 FC,其输出的是对应类别(假设预测是类)的 bbox: ,给定 类的真实框 ,损失函数为
其中,Smooth L1 损失为
Attention
- 在这里使用 L1 而不使用 L2 的原因是前者对 outliers 不敏感。当物体没有被框框住的时候,用 L2 优化需要特殊处理(防止梯度爆炸),因此选择使用 L1。
- 这里的类别 u 必须要大于 1,0 作为「背景」没有回归框,所以当 u=0 时,
- 在实践中,作者将真实框进行了归一化以获得0均值和单位方差(原因是什么?)
综上,总的损失函数为两个损失的和
其中,为超参,本为中
训练细节
构建 mini-batch
对于每个Mini-batch
- 从 N=2 张图上采样 128 个 Region Proposals,平均每张图像 64 个。其中 25%为含有物体的 Region Proposals(正样本, ),剩下 75%的是背景(负样本, ),即正负样本比为3:1
- 正样本:若一个 Region Proposal 和某个 bbox 真值的 IoU 值>0.5,即程这个 Region Proposal 为正样本
- 负样本:若一个 Region Proposal 和任何 bbox 真值的 IoU 值在 范围内,即程这个 Region Proposal 为负样本
- 以上正负样本定义仅对本工作生效。
- (数据增强) 0.5 的概率水平翻转图像
相关超参数
- The fully connected layers used for softmax classification and bounding-box regression are initialized from zero-mean Gaussian distributions with standard deviations 0.01 and 0.001, respectively.
- Biases are initialized to 0.
- learning rate = 1e-3 training 30k iterations, then lr = 1e-4 for another 10k on VOC07 or VOC12 trainval.
- A momentum of 0.9 and parameter decay of 0.0005 (on weights and biases) are used.
Back-propagation through RoI pooling layers
没有仔细看
Scale invariance
没看懂在讲什么…
Truncated SVD for faster detection
截断 SVD
经作者统计发现,由于RoI Pooling后经Resize的Feature vector维度太大,导致FC层推理速度很慢,因此作者通过引入截断SVD的技术,将一个大的FC变成两个小的FC,进一步加速了网络在FC部分的推理速度。
Experiments
几个实验结论
- 底层的网络层(本文中特指 conv1)学到的更多是通用且任务独立的特征
A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012. 1, 4, 6
- 仅仅只 fine-tune fc6 结果并不是最好的,连同一些卷积层一起 fine-tune 效果会有提升

- 本文中,Multi task loss 显著提升算法表现
- 训练数据越多,结果越好
- 使用 Softmax 做分类比使用 SVM 效果要好上一点点,但是使用 softmax 能够做端到端,而不必分阶段
- 使用过多的 Region Proposals 对分类器并不一定有好处,还可能略有伤害(文中比较了 SS 和 DPM 两种提取 Region Proposals 的方法)
Some Descriptions
- Due to this complexity, current approaches train models in multi-stage pipelines that are slow and inelegant.
- We call this method Fast R-CNN because it’s comparatively fast to train and test.
- First, let’s elucidate why SPPnet is unable to …
- We call this network model M, for “medium.”
Footnotes
-
之前的方法都是多阶段的方法,因此需要将特征缓存起来,最后统一做预测和分类。 ↩